
研究 - 用中文驱动 LLM 是否效率更高
近期,一朋友接了领导的研究任务,主题是中文之于大语言模型的领先性。
缘起是 2025 年 1 月,DeepSeek 的新版本惊艳了 AI 业界,中文大模型一夜封神。之后,Qwen 3、K2 等模型的屡次屠榜,证明国人强于数学与 AI 工程学并非偶然。
除了对中国 AI 科研人员的艳羡和赞美之外,群众不禁追问:既然汉字可考历史超过3500年,相比拉丁文字,中文是否有表达信息的内生优势?DeepSeek 等模型的成功,是否很大程度上得益于在预训练阶段融入了中文字符?
若将“中文 AI 优越论”,归因于历史必然、内在必然,无疑让华语互联网文化自信又增。
汉字是否更为简洁
2025年2月,新加坡《南华早报》引电信业意见领袖项立刚的论述说,“汉字以最小的成本实现最大信息传递。作为一种高效的信息编码,中文在人工智能处理中极大地提高了效率并降低了成本。”
知名学者张维为在《这就是中国》第274期圆桌讨论中,用他在联合国的工作经历举例。
“《联合国宪章》,有六种官方语言版本,中文是最薄的。道理非常简单,因为中文核心汉字只有3500个左右,掌握后就可以阅读所有报刊,而读《纽约时报》至少需要掌握2万个英文单词,否则会读得非常累。”
专家们的看法,汉字字符是中文信息密度大于英文的根因之一。
计算机处理英文,最小信息单元是字母;处理中文,最小信息单元是单字(而非偏旁部首,偏旁部首不单独编码)。除却缩写,字母本身并不承载意义,单个汉字却承载意义。因此,汉字在计算机中编码效率高于字母,有其基本逻辑。
用计算机指令类比,英文相当于 RISC 体系,汉语则为 CISC 体系。
网络上关于“谁表述更简洁,英文还是中文?”的话题,众说纷纭。汉语以意合,英语以形合,根基不同,长短不一。
双方都有生动的例子。但胜负断言缺乏量化统计依据。
至于《联合国宪章》,1945年的初始版本,英文、法文30页,中文28页,俄文32页。却不能作为汉语简约的可靠论据。字体大小,排版风格皆能决定文本厚薄。英文单词占位较宽,体积大过汉字字符,在比较中颇为吃亏。


在最常用的计算机信息存储标准 UTF-8 编码下,一个英文字母占一个8位字节,而一个汉字占2~4个字节不等。单个汉字相对单个英文字母并不占空间优势。
表达相近意义的双语文本,在同一套 UTF-8 编码下,消耗的存储容量,谁多谁少?其实很容易以书籍素材为基础,肩并肩量化比较。
我做了三类计数。
- 第一,比较中文名著及其英文译文,总体来看,英文字符消耗量为中文3倍以上。
| 标题 | 源语言 | 目标语言 | 原文字符数 | 译文字符数 | 译/原比例 |
|---|---|---|---|---|---|
| 鲁迅全集 | 中文 | 英文 | 5873812 | 16880074 | 2.87 |
| 毛泽东选集 | 中文 | 英文 | 1891939 | 6230272 | 3.29 |
| 三国演义 | 中文 | 英文 | 658034 | 2530469 | 3.85 |
| 水浒传 | 中文 | 英文 | 853834 | 3074865 | 3.6 |
| 西游记 | 中文 | 英文 | 815930 | 2854097 | 3.5 |
| 红楼梦 | 中文 | 英文 | 1120253 | 3604908 | 3.22 |
| 11213802 | 35174685 | 3.22 |
- 第二,英文非小说类畅销书,及其中文译文。英文字符消耗量约为中文2.5倍。
| 标题 | 源语言 | 目标语言 | 原文字符数 | 译文字符数 | 原/译比例 |
|---|---|---|---|---|---|
| Empire of AI | 英文 | 中文 | 941609 | 407678 | 2.31 |
| The Art of Asking | 英文 | 中文 | 90134 | 33032 | 2.73 |
| Brave New Words | 英文 | 中文 | 322667 | 120429 | 2.68 |
| The Creative’s Mind | 英文 | 中文 | 353149 | 135431 | 2.61 |
| Sketch Your Mind | 英文 | 中文 | 230130 | 97376 | 2.36 |
| Blood in the Machine | 英文 | 中文 | 784294 | 305211 | 2.57 |
| Emergence | 英文 | 中文 | 463661 | 171274 | 2.71 |
| The Socratic Method Today | 英文 | 中文 | 572560 | 225475 | 2.54 |
| Guide to Analytic Thinking | 英文 | 中文 | 72681 | 25373 | 2.86 |
| Selfhood in the Digital Age | 英文 | 中文 | 515779 | 195126 | 2.64 |
| The Neural Mind | 英文 | 中文 | 794381 | 327877 | 2.42 |
| Breaking Things at Work | 英文 | 中文 | 275300 | 109307 | 2.52 |
| The AI Con | 英文 | 中文 | 509834 | 238019 | 2.14 |
| The Enigma of Reason | 英文 | 中文 | 717349 | 279940 | 2.56 |
| Dead Money | 英文 | 中文 | 566693 | 232112 | 2.44 |
| Not a Kinesthetic Learner | 英文 | 中文 | 510630 | 189561 | 2.69 |
| The Thinker’s Guide | 英文 | 中文 | 173563 | 61454 | 2.82 |
| 7894414 | 3154675 | 2.5 |
- 第三,最近多期《自然》杂志,原文档为英文。其字符消耗量为中文2.2倍。
| 标题 | 源语言 | 目标语言 | 原文字符数 | 译文字符数 | 原/译比例 |
|---|---|---|---|---|---|
| Nature [Sun, 27 Jul 2025] | 英文 | 中文 | 1751308 | 801169 | 2.19 |
| Nature [Sat, 30 Aug 2025] | 英文 | 中文 | 1866253 | 862091 | 2.16 |
| Nature [Tue, 12 Aug 2025] | 英文 | 中文 | 1960390 | 871506 | 2.25 |
| Nature [Sun, 29 Jun 2025] | 英文 | 中文 | 1750108 | 811688 | 2.16 |
| Nature [Sat, 23 Aug 2025] | 英文 | 中文 | 1483214 | 678719 | 2.19 |
| Nature [Sat, 19 Jul 2025] | 英文 | 中文 | 1434444 | 658810 | 2.18 |
| Nature [Sat, 16 Aug 2025] | 英文 | 中文 | 1905335 | 860145 | 2.22 |
| Nature [Sat, 06 Sep 2025] | 英文 | 中文 | 2148336 | 969359 | 2.22 |
| 14299388 | 6513487 | 2.2 |
为统计一致性,以上翻译均为同一 LLM 引擎完成。
从结果看,汉字字符整体效率高于英文字母。对不同领域的文本,体现有差异。
中文名著,信息密度最高,原因有可能是四大名著夹杂少许文言文表述,英文翻译用掉更多文字。然而,《毛泽东选集》依然平均一个汉字耗掉 3.29 个英文字母,超过《红楼梦》(3.22)。
英文畅销书与机翻中文对照,字母、汉字所占用空间比率为 2.5,符合项立刚老师的逻辑。
对于科学文章属性的《自然》杂志,不少科学名词用英文缩写,而译为中文名称变长。因此,汉字的信息简约性优势略微变弱,但仍保持 2.2 倍的空间比率优势。
分词技术曾经的“偏见”
故事本可以在这里结束。但 SemiAnalysis 的创始人 Dylan Patel 持不同意见。
Dylan Patel 何方神圣?他是如今 AI 和半导体领域最受关注的独立分析师之一。
Dylan 在 2023 年 7 月29 日的推文中讲:LLM 推理成本因语言不同而差异巨大,对于 GPT-4 和大多数其他常见 LLM 来说。英语是最便宜的。中文是英语的两倍。其他语言,如缅甸语,差距可达夸张的 15 倍。其原因是,大语言模型的”分词“机制,表达同一个意思,英语占用更少数量的词元(Token)。
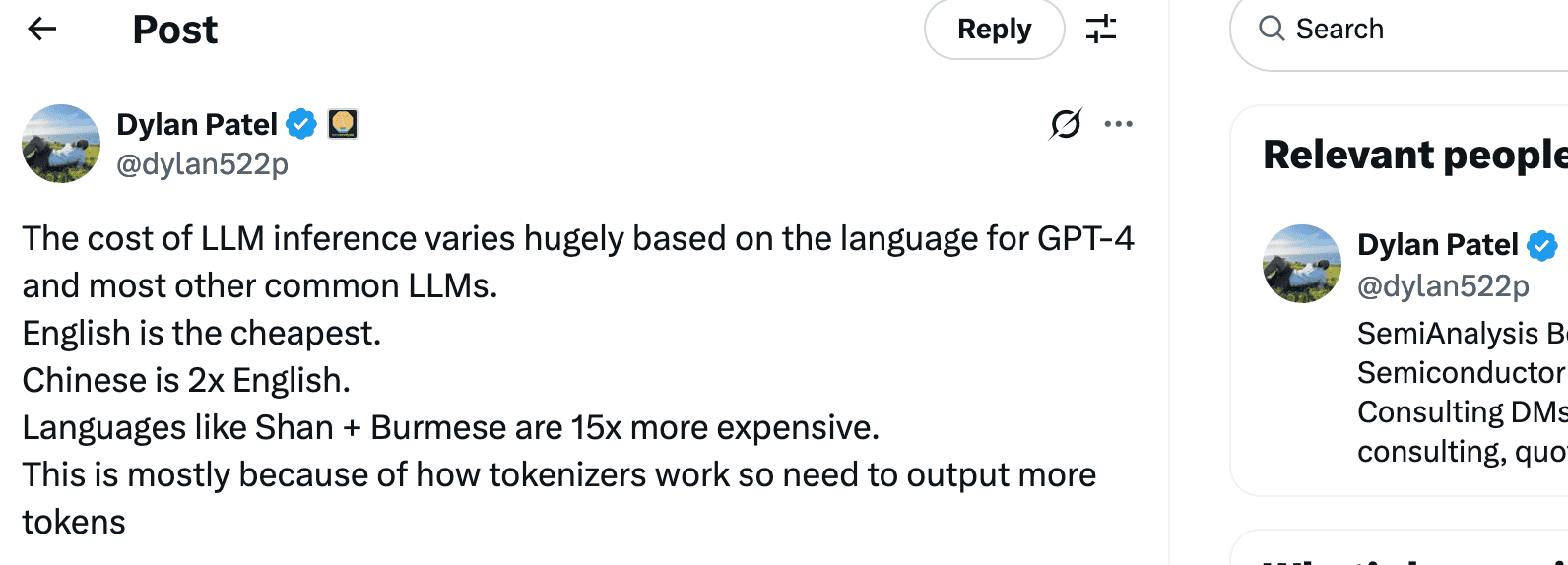
Dylan 的论述源于一篇来自牛津大学的论文“Language Model Tokenizers Introduce Unfairness Between Languages”。
仔细读来,该论文并无彰显英语优越感之意,反而指出了 OpenAI 等厂商的大模型因分词技术原因,对非英语语种带来不公平。
我上面统计比较一本书的多语版本,“英文字符数” vs. “中文字符数”,除影响计算机存储空间外,于大语言模型并无意义。
原因是,在 LLM 内,处理的最小信息单元,并非单个英文字母,亦非汉字,而是分词器(Tokenizer)产生的词元(Token)。
准确地讲,模型用来推理的数据,是词元对应的“高维嵌入式表示”(Embedding)。
“嵌入表示”涉及到大模型为何能推理出有意义文本的根本原因,在此不加冗述。但“词元”很容易理解。
根据 OpenAI 和其他主流模型服务商的 BPE 分词算法,在大量语料中相邻的、共现频率高的字母和符号会被聚集在一起,像雾气凝聚为露珠,形成一个个“词元”。
据实际观察,很多英文单词,频繁亮相的短语会被认为是单一词元。
OpenAI 提供了网页工具,演示了如何分词。https://platform.openai.com/tokenizer
不仅对分词的结果数量进行了统计,而且用不同的颜色区分展示了具体结果。
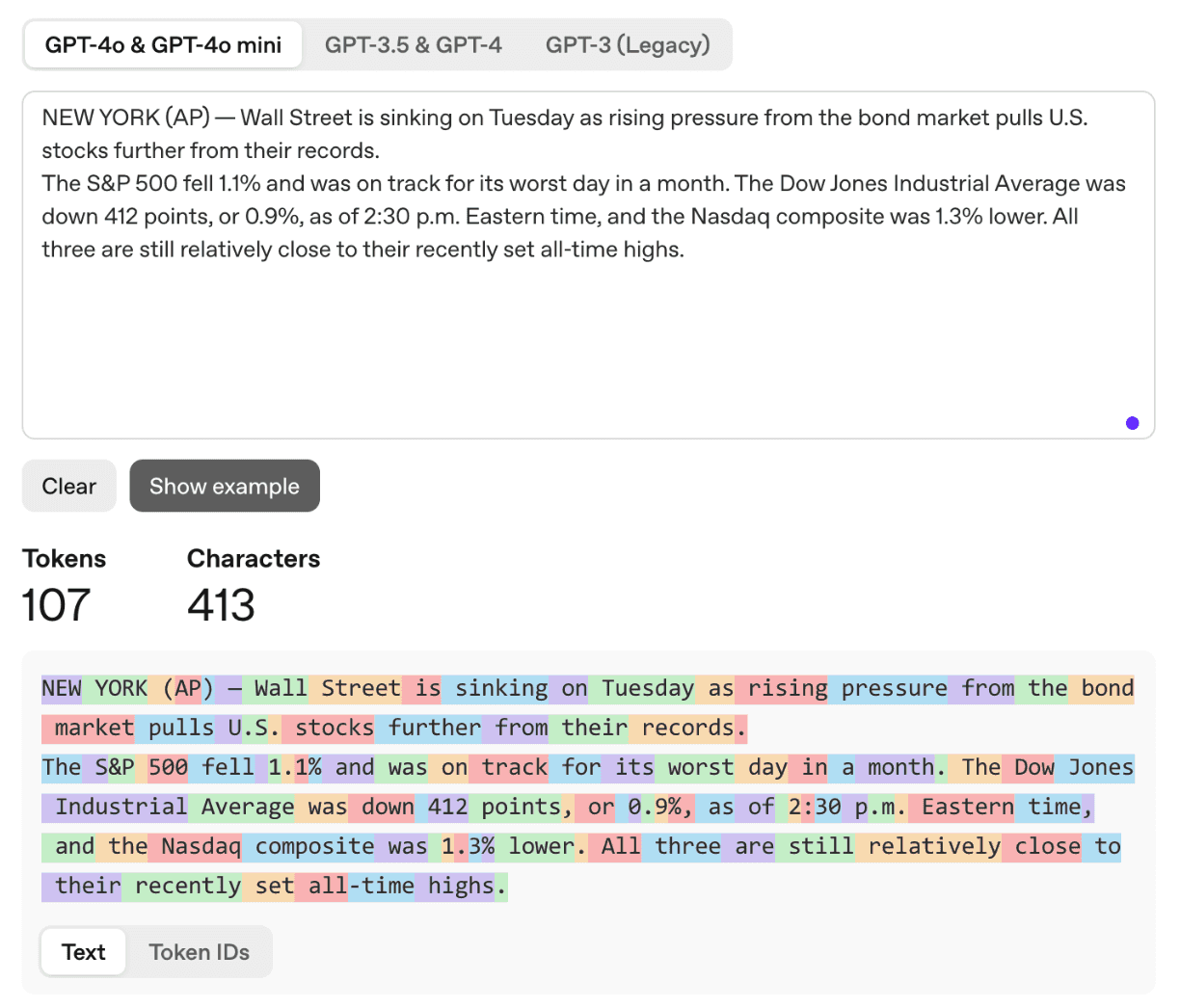 以上图中,输入框区域,用户可以键入测试文本。上面的句子来自于《财富》杂志9月3日的公开新闻。总共 413 个字符,分词器将其划为 107 个词元。
以上图中,输入框区域,用户可以键入测试文本。上面的句子来自于《财富》杂志9月3日的公开新闻。总共 413 个字符,分词器将其划为 107 个词元。
数字、标点的分词方式较为有趣,“500”、“30”被视为一个词元,而独立的单个数字则被分为单个词元。一般来说,标点被分为单个词元,但临近的标点,被合并为一个词元,如“%,”。
界面提供了三代GPT模型的比较,对英文而言,GPT-5 的分词器没有提供,但 GPT-4o及之前的三代模型,分词方式没有变化。
这个演示内容也适合于中文。以下测试内容摘自《上海证券报》新闻。
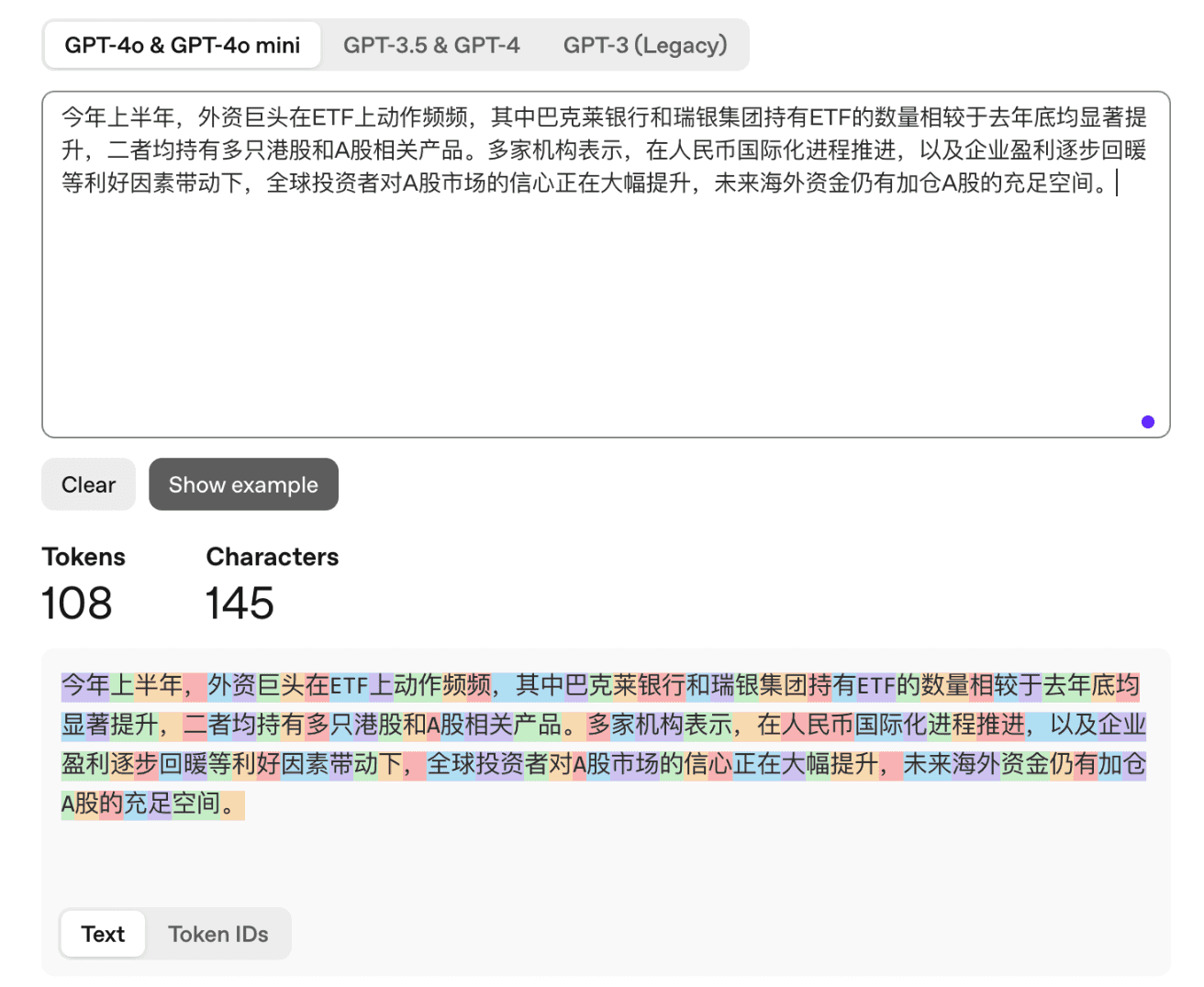
值得关注的是,同一段话,不同代次的 GPT 模型对中文的分词效率不同。

同样的 145 个中文字符(汉字+标点),GPT-3 消耗了 307 个 词元,GPT-3.5/4 消耗 169 个词元,而现行的 GPT-4o 仅消耗 108 个词元。
处理中文,GPT-3 的词元占用量是汉字字数的约两倍。GPT-3.5/4 基本上是一个字一个词元。
而 GPT-4o,从结果演示来看,它把汉字组成的常用词进行了一些合并。用单个词元表示中文一个词,类似于英文单词的处理方式。因此,GPT-4o 处理中文,词元消耗量大幅度下降。
Dylan Patel 和 牛津研究人员批评的是 2023 年 7月的 GPT-4。可见,OpenAI 的研发人员聆听了社区的声音,已改进了中文等语言的分词效率。
随着 OpenAI 的悔改,“中文 Token 数消耗量是英文的两倍”,这个现象可封存为历史。
固定“意义”下,哪种语言更优?
信心值重新加满,回到那个根本问题,大模型中,传递同样信息,用哪种语言更有效率?
表达同样意义的一段文本,哪种语言文字的词元消耗更少,中文,还是英文?
要做相同含义的多语种内容,做大模型分词的效率比较,首先要找到权威的对照翻译文本。
如果找一段英文,机翻为中文,比较两者,不一定准确客观。因为机翻的性能有限,不同模型,也有简洁或者啰嗦的各自特点。
如果以文学作品为依据,从母语版本到译本,无论任何名家翻译,都有“信、达、雅”程度的不确定性。翻译专家也难免夹带私货,遑论机翻。
一个优质素材是联合国的官方网站。
https://www.un.org/ 提供了六种语言的对照版本。联合国是多边的舞台,价值观的交集,信息解读相对中立。对照的公文和新闻发布,内容可基本做到“不杂不漏”。
我们从 UN 网站的“支持可持续发展与气候行动”页面摘取一段引言,用作“苹果对苹果”的实验。
英文网址在:https://www.un.org/en/our-work/support-sustainable-development-and-climate-action
中文网址在:https://www.un.org/zh/our-work/support-sustainable-development-and-climate-action

结果表明,在同一意义表达的限定下,中文使用的计算机字符数仅为英文的 1/3 到 1/4 ,并不意外,这是汉字之于英文字母的信息编码密度优势。
而折算为 GPT-4o 模型下的词元,结果有所不同。表达同一意义,英文使用了 182 个词元,而中文用了 197 个词元。英文反而有微弱优势。
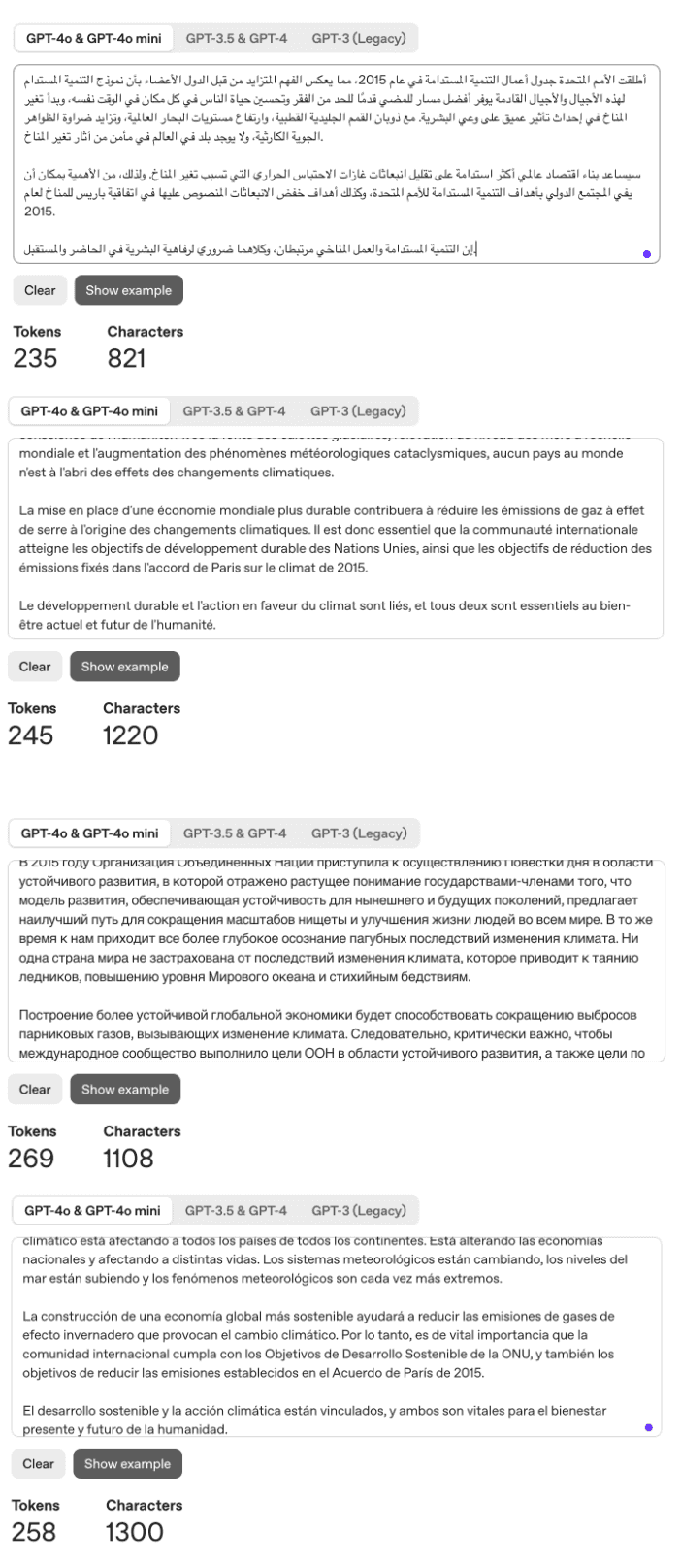 中文用户倒是不要气馁。相对其他 4 种联合国语言,中文在次新版 GPT 模型下的分词效率优势非常明显,与榜首接近。
中文用户倒是不要气馁。相对其他 4 种联合国语言,中文在次新版 GPT 模型下的分词效率优势非常明显,与榜首接近。
| 英文 | 中文 | 阿拉伯语 | 法语 | 俄语 | 西语 | |
|---|---|---|---|---|---|---|
| 词元数 | 182 | 197 | 235 | 245 | 269 | 258 |
| 字符数 | 1024 | 276 | 821 | 1220 | 1108 | 1300 |
这是 OpenAI 的分词器效果,我们进而追问,以 DeepSeek 为代表的国产大语言模型,在分词的问题上表现如何。
好在,DeepSeek、Kimi、Qwen、智谱等模型的分词器皆在 Huggingface 开源。OpenAI 也提供了 ticktoken Python 库,作为线下分词研究工具。
我略花了一点时间,vibe 了一个小程序,比较了上述文本在各个模型下的分词统计。结果如下:
| 模型名 | 字符长度 | 分词长度 | 压缩比 |
|---|---|---|---|
| gpt-4o | 276 | 197 | 1.40 |
| gpt-4/gpt-3.5 | 276 | 330 | 0.84 |
| gpt-3 | 276 | 594 | 0.46 |
| deepseek-v3.1 | 276 | 140 | 1.97 |
| kimi-k2 | 276 | 133 | 2.08 |
| qwen3 | 276 | 153 | 1.80 |
| glm-4.5 | 276 | 142 | 1.94 |
拾回自信的时刻终于到来,四大国产模型处理中文分词的效率碾压 OpenAI。同样的 276 个汉字,它们的分词长度在 133 到 153 之间,K2 模型位居效率第一。
国产模型不仅大幅领先 GPT-4o 处理汉字的 197,而且超过了它对英文母语的处理(182)。
当然, OpenAI 的 SOTA,GPT-5 的分词器尚未公开。
然而,一段仅276汉字(1024个英文字母)的信息,不具代表性和普遍性,并不能说明中文和英文的对比效率。
于是我抓取了 http://un.org 下的主要内容,萃取文本,去除标签和链接。大概有51个页面,包括联合国机构描述、宪章、国际法庭、人权宣言、重要事件描述等重要文件。这些页面都有严格的六种语言对照。
萃取结果数据,每条皆以人工仔细对比,以免遗漏错位。
最终,输入源变成英文305064个字符,而中文为91089个字符。用它们来做信息效率研究应该能体现公平。
运行结果如下:
| 模型名 | 语言类型 | 字符数 | 分词数 | 压缩比 |
|---|---|---|---|---|
| gpt-4o | 英文 | 305064 | 62458 | 4.88 |
| gpt-4/gpt-3.5 | 英文 | 305064 | 62984 | 4.84 |
| gpt-3 | 英文 | 305064 | 68966 | 4.42 |
| deepseek-v3.1 | 英文 | 305064 | 62448 | 4.89 |
| kimi-k2 | 英文 | 305064 | 62921 | 4.85 |
| qwen3 | 英文 | 305064 | 65847 | 4.63 |
| glm-4.5 | 英文 | 305064 | 62928 | 4.85 |
| gpt-4o | 中文 | 91089 | 65692 | 1.39 |
| gpt-4/gpt-3.5 | 中文 | 91089 | 96029 | 0.95 |
| gpt-3 | 中文 | 91089 | 182237 | 0.50 |
| deepseek-v3.1 | 中文 | 91089 | 51466 | 1.77 |
| kimi-k2 | 中文 | 91089 | 49511 | 1.84 |
| qwen3 | 中文 | 91089 | 56965 | 1.60 |
| glm-4.5 | 中文 | 91089 | 52456 | 1.74 |
可见,GPT-4o 表达这些联合国官方文本,用的英文分词数仍然略多于中文(62458 < 65692)。但所有的中国开源模型效率都高过 GPT-4o,尤以 K2 为甚。
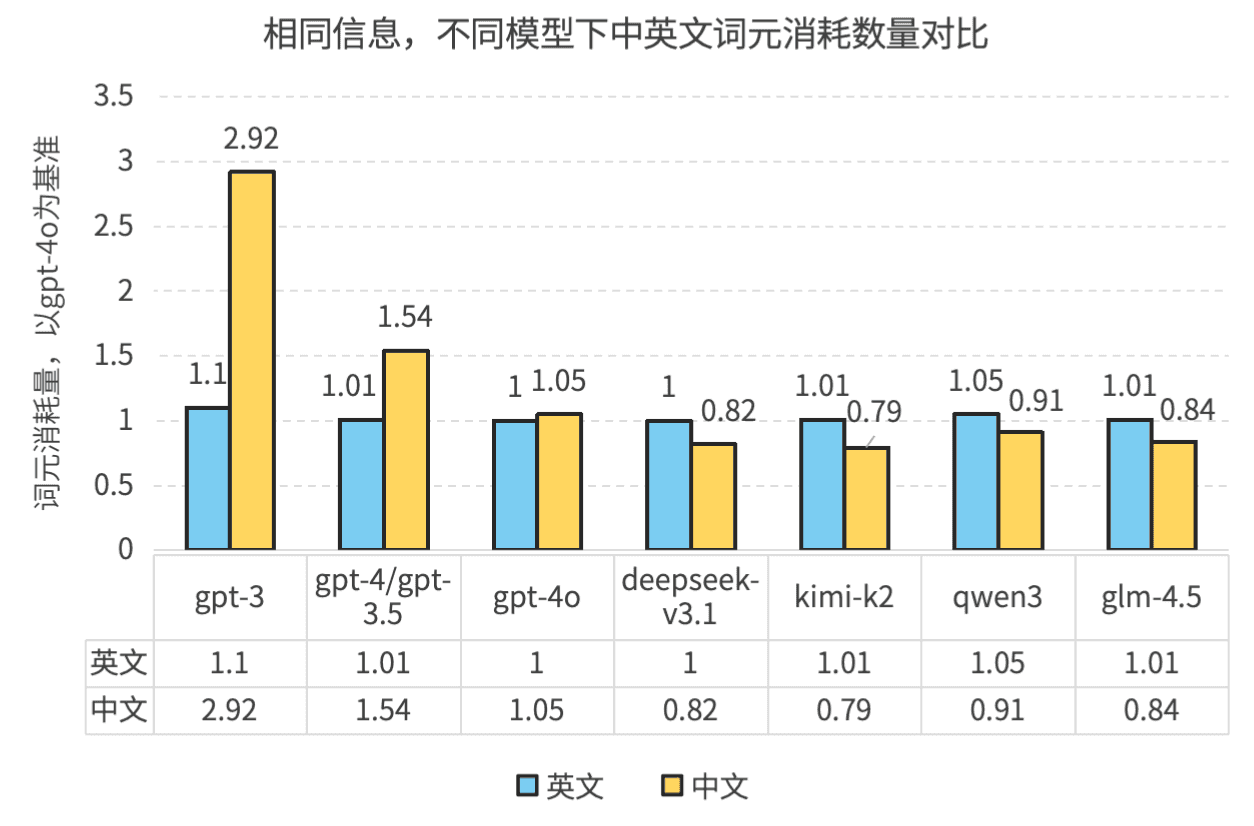
以下是一个更直观的图像展示,以 GPT-4o 为基准。我们可以读出,DeepSeek V3.1、K2、Qwen 3、GLM-4.5 这些模型处理中文的效率普遍比 GPT-4o 高出 10% 以上。处理英文方面,DeepSeek 与 GPT 效率相当,其他模型略弱,但差距微小。
更重要的发现是,在 DeepSeek V3.1、K2、Qwen 3、GLM-4.5 这些模型之下,中文词元的整体信息密度全部高于英文,至少 15%。
通过阅读技术报告可知,Qwen 等模型皆在 BBPE 分词算法上作了优化,这是它们中文分词效率更高的原因。
结论:中国大模型 + 汉语 = 低碳
折腾了半天,有何结论?
- GPT 较新的模型,中文和英文的信息表达效率已差距不大,仍略弱。
- 在国产模型下,中文信息表达效率已超出英文 15%~20%。
也就是说,我们用 DeepSeek 这些国产大模型,解决同样的问题,其他变数固定的情况下,用中文对话,至少节省 1 成以上的 Token。
绕了一圈,张维为、项立刚老师的论断,部分成立。至少是,在使用最新的主流国产开源大模型这一条件下成立。
中文的 AI 优势,并不能只靠老祖宗的恩赐,国产大模型让中文内生的高效信息表达得以实现。
这有何意义?
中文的碳足迹更轻,更少的词元消耗,更为环保,会有利于碳中和。
根据联合国教科文组织的研究,每条大模型提示词的运行平均消耗 0.34 瓦时的电量,大概相当于 0.04 克二氧化碳。
这看起来微不足道,但每天全球有超过 10 亿人在同时使用生成式人工智能。
累积起来每年高达 310 吉瓦时,相当于一个低收入非洲国家超过 300 万人每年的电力消耗。
如果在聊天过程中省掉 10% 的词元,至少能提供惠及 30 万非洲群众的电力!

为了一个绿色的地球,我们应号召全球科技界学习中文,并使用中国产的大语言模型。
参考资料
Alibaba. 2025. “Qwen3 Technical Report.”
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, et al. 2024. “DeepSeek-V3 Technical Report.” arXiv. https://doi.org/10.48550/arXiv.2412.19437.
Dylan Patel. 2023. “The Cost of LLM Inference Varies Hugely Based on the Language for GPT-4 and Most Other Common LLMs. English Is the Cheapest. Chinese Is 2x English. Languages like Shan + Burmese Are 15x More Expensive. This Is Mostly Because of How Tokenizers Work so Need to Output More Tokens Https://T.Co/Y7De09pb4w.” Tweet. Twitter. https://x.com/dylan522p/status/1685038026228129796.
Petrov, Aleksandar, Emanuele La Malfa, Philip H. S. Torr, and Adel Bibi. 2023. “Language Model Tokenizers Introduce Unfairness Between Languages.” arXiv. https://doi.org/10.48550/arXiv.2305.15425.
“Strokes of Genius: Why Chinese Lessons May Make DeepSeek’s AI Smarter.” 2025. South China Morning Post. February 14, 2025. https://www.scmp.com/news/china/science/article/3298555/strokes-genius-why-deepseeks-ai-edge-may-come-its-chinese-lessons.
Team, Kimi, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, et al. 2025. “Kimi K2: Open Agentic Intelligence.” arXiv. https://doi.org/10.48550/arXiv.2507.20534.
UN. 1945. “联合国宪章全语言初始版本.”
UNESCO. 2025. “Smarter, Smaller, Stronger: Resource-Efficient Generative AI & the Future of Digital Transformation.” UNESCO. https://unesdoc.unesco.org/ark:/48223/pf0000394521.
张维为. 2025. “张维为《这就是中国》第274期| DeepSeek震撼-张维为、汪涛.” March 2025. https://www.guancha.cn/ZhangWeiWei/2025_03_16_768588_s.shtml.
